[JAVA] Stream
Stream이란?
자바8 이상부터 사용 가능한 데이터의 흐름이다.
Stream을 사용하면 배열과 컬렉션 인스턴스에 대한 반복작업을 for문 보다 짧고 간결하게, 다양한 라이브러리 함수를 조합해서 편리하게 작성이 가능하며, 간단하게 병렬처리를 할 수 있다.
Stream 실행 과정
Stream은 스트림 인스턴스 생성 -> 가공(필터링, 맵핑 등의 원하는 작업) -> 결과(작업한 결과물을 반환하면서 스트림 종료)
Stream 생성
배열 스트림
String[] arr = new String[]{"a", "b", "c"};
Stream<String> stream = Arrays.stream(arr);
Stream<String> streamOfArrayPart = Arrays.stream(arr, 1, 3); // 1~2 요소 [b, c]컬렉션 스트림
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
Stream<String> parallelStream = list.parallelStream(); // 병렬 처리 스트림빈 스트림
stream() 대신 streamOf(List)를 통해 생성할 수 있다.
내부적으로 null에 대한 검사를 진행하기 때문에 인스턴스가 null인 경우 빈 스트림을 생성해주고, null이 아닐 경우stream()을 호출한다.
생성과 동시에 값 추가
Stream.builder()
직접 추가할 요소를 지정하는 방식
Stream<String> builderStream = Stream.<String>builder()
.add("Eric").add("Elena").add("Java")
.build(); // [Eric, Elena, Java]Stream.generate()
요소를 지정한 개수만큼 추가하는 방식 (스트림 크기가 무한하기 때문에 limit를 줘야한다)
Stream<String> generatedStream =
Stream.generate(() -> "gen").limit(5); // [gen, gen, gen, gen, gen]Stream.iterate()
람다를 사용해서 초기값에서 규칙적으로 변경하여 값을 넣을 수 있다. (스트림 크기가 무한하기 때문에 limit를 줘야한다)
Stream<Integer> iteratedStream =
Stream.iterate(30, n -> n + 2).limit(5); // [30, 32, 34, 36, 38]
그 외
컬렉션 같은 제네릭 외에도 IntStream, FileStream과 같은 지정된 타입의 스트림도 존재하며, ParallelStream()으로 병렬 스트림을 생성할수도 있고, Stream.concat(stream1, stream2)로 스트림을 연결하여 새로운 스트림을 만들 수도 있다.
데이터 가공
Filtering
제외하고 싶은 요소들을 걸러내는 작업으로 filter 메소드 내부에서 람다를 통해 원하는 필터링 규칙을 지정할 수 있다.
Stream<String> stream =
names.stream()
.filter(name -> name.contains("a"));
//이름에 "a"가 포함된 요소들을 제외한 stream 생성Mapping
스트림 내 요소들을 하나씩 특정 값으로 변환해준다. 이 때 값을 변환하기 위한 람다를 인자로 받는다.
Stream<Integer> stream =
productList.stream()
.map(Product::getAmount);
//Product 객체의 Amount를 가져와서 Integer Stream [23, 14, 13, 23, 13] 생성요소의 요소를 가지고 새로운 스트림을 만들어낼 수 있다. (객체라면 객체의 특정 필드만 변환해서 새로운 스트림을 만들 수 있다.)
List<List<String>> list =
Arrays.asList(Arrays.asList("a"),
Arrays.asList("b"));
// [[a], [b]]
List<String> flatList =
list.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList());
// [a, b]
//리스트에 리스트가 있을 때 두 리스트를 하나로 연결해서 단일 리스트로 만들어 줄 수 있다.
//List<List<String>> => List<String>Sorting
정렬도 가능하다.
list.stream()
.sorted(Comparator.comparingInt(String::length))
.collect(Collectors.toList());
//String의 길이로 정렬
결과 생성
계산을 통해 결과 값을 가져올 수도 있고, 컬렉션으로 변환하여 값을 가져올 수도 있으며, 다양한 방법이 있다.
다 적어놓고 보는 것 보다 위 내용들을 통해 필요한 값을 만들어내고 마무리로 반환하고 싶은 결과에 따라 검색해보며 익히는 것이 좋을 것 같다.
동작 순서
Stream<String> builderStream = Stream.<String>builder()
.add("Eric").add("Elena").add("Java")
.build(); // [Eric, Elena, Java]
builderStream
.filter(el -> {
System.out.println("filter: " + el);
return el.contains("a");
})
.map(el -> {
System.out.println("map: " + el);
return el.toUpperCase();
})
.findFirst().ifPresent(System.out::println);
//filter: Eric
//filter: Elena
//map: Elena
//ELENA1. Eric이 첫 번째로 들어와서 a를 포함하지 않기 때문에 filter를 출력하고 다음 요소로 넘어간다.
2. Elena는 a를 포함하기 때문에 filter를 출력하고 map에 들어가서 map을 출력한다.
3. findFirst()는 첫 번째 요소만을 반환하는 연산이기 때문에 Elena가 return 되면서 최종적으로 ELENA가 출력된다.
즉, filter()가 전부 수행되고 결과값에 map이 수행되는 것이 아니라 filter와 map이 하나의 파이프라인으로 이어져있다.
하나의 요소가 순서대로 filter -> map -> findFirst를 지나는 과정을 반복하는 것이다.
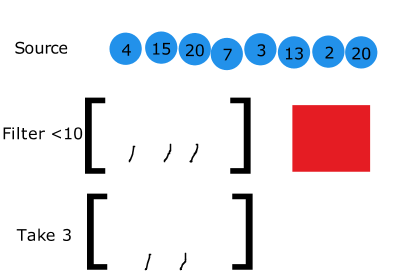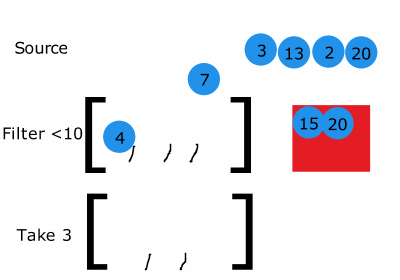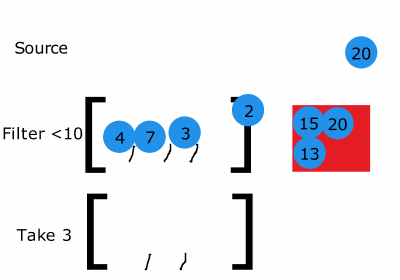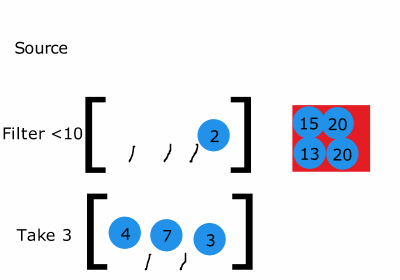
성능 향상
스트림은 한 요소가 순차적으로 모든 파이프 라인을 지나간다.
그렇기 때문에 stream의 사이즈를 많이 줄일 수 있는 로직이 앞에 위치한다면 반복 횟수를 줄일 수 있다.
위 동작 순서의 예제 코드에서 findFirst() 대신 .collect(Collectors.toList());를 넣고 실행하면 5번의 출력이 나오는 것을 볼 수 있는 반면, map과 filter의 순서를 바꾸면 Eric이 생략되는 과정이 빠져 6번의 출력이 발생한다.
지연 연산 Lazy evaluation
동작 순서의 예제 코드에서 결과 값을 생성하는 코드 findFirst를 뺀다면 결과값은 0으로 아무것도 출력되지 않는다.
이유는 스트림은 반드시 결과 생성코드로 마무리해야하고, 지연 연산으로 인해 filter -> map -> collect를 통해 collect가 실행되고 나면 그제서야 실제 filter와 map의 연산을 실행하기 때문이다.
처음에 이 개념을 듣고 그럼 filter에서 걸러지면 map에 못가는거 아니야? 라고 생각했지만, 실제 filter 내부 연산을 진행하면서 결과 생성 코드로 가는 것이 아닌 참조를 통해 탐색하는 것이라서 collect와 같은 결과 생성 코드까지 갈 수 있다.
그렇기 때문에 collect까지 호출되어도 filter와 map의 출력 문장이 실행되지 않는 것이다.
스트림 재사용
스트림은 종료 작업을 하지않으면, 하나의 인스턴스로써 계속해서 사용이 가능하다. 하지만 종료 작업을 하는 순간 스트림이 닫히기 때문에 재사용할 수 없다.
이유는 스트림은 데이터를 저장하는 것이 목적이 아니라 데이터를 처리하는 것이 목적이기 때문이다.
저장을 하고싶다면 .collect(Collectors.toList()); 와 같은 결과 생성 코드로 결과값을 변수에 저장하면 된다.
Null Safe 스트림
//collectionToStream
public <T> Stream<T> collectionToStream(Collection<T> collection) {
return Optional
.ofNullable(collection)
.map(Collection::stream)
.orElseGet(Stream::empty);
}
//사용
List<Integer> intList = Arrays.asList(1, 2, 3);
List<String> strList = Arrays.asList("a", "b", "c");
Stream<Integer> intStream =
collectionToStream(intList); // [1, 2, 3]
Stream<String> strStream =
collectionToStream(strList); // [a, b, c]collectionToStream()을 통해 스트림을 생성하면 내부적으로 Optional 처리가 되어있어 Null Pointer Exception을 방지할 수 있다.